La memoria se puede representar como una coleccion de celdas contiguas con la capacidad de almacenar valores. Cada celda de memoria es individualizada por una 'direccion', que consta de un valor de segmento y otro de offset (desplazamiento dentro del segmento). Los detalles de como opera la cpu en relacion a la memoria dependen del tipo de procesador, si este esta funcionando en modo 'real' o 'protegido', sistema operativo y muchos otros factores.
Cada segmento tiene una capacidad de 64 Kb. Una importante directiva en todos los programas es la que determina el MODELO DE MEMORIA que utilizara el programa al ejecutarse. El default suele ser el modelo 'small', pero existen varios modelos mas, sus principales diferencias estan en el modo en que utilizan los segmentos para almacenar codigo, datos o ubicar la pila (stack).
Al compilar y ejecutar un programa, en el IDE de TurboC++, podemos examinar los registros de la CPU para datos, codigo y stack, estas son las siglas de tales registros:
| CS (code seg) | Segmento de codigo |
| DS (date seg) | Segmento de datos |
| SS (stack seg) | Segmento de pila |
El modelo de memoria utilizado por nuestro programa determinara cuanto espacio (en termino de segmentos) se usara para codigo, datos y stack. El siguiente cuadro sintetiza las distintas opciones:
| Modelo de memoria | Segmentos | Comentarios |
| Tiny | cs = ds = ss | Codigo, datos y stack utilizan un unico segmento, por lo tanto el ejecutable
no podra ser mayor a 64 Kb. Es muy similar a un ejecutable con extension .COM |
| Small | cs ds = ss |
Un segmento para codigo y uno para datos y stack. Es el modelo default utilizado, a menos que se especifique uno diferente. |
| Medium | cs ds = ss |
Codigo usa multiples segmentos, datos y pila comparten uno. Es el modelo de eleccion si hay gran cantidad de codigo y pocos datos |
| Compact | cs ds = ss |
Un segmento para codigo y multiples segmentos para datos y stack. Modelo apropiado cuando hay poco codigo pero gran cantidad de datos. Los datos son referenciados por punteros 'far' |
| Large | cs ds = ss |
Multiples segmentos para codigo y multiples seg para codigo y stack.
Se usan punteros 'far' para codigo y para datos |
| Huge | cs ds = ss |
Similar a 'large' |
| Flat | cs ds = ss |
Usa punteros 'near' como el modelo 'small', pero hecho a medida para
sistemas operativos de 32 bits |
Estas categorias no son especificas de un lenguaje de programacion, la mayoria de los compiladores de los diferentes lenguajes permiten optar por estos diferentes modelos de memoria. Las primeras versiones TurboC++ admiten solo los primeros seis modelos de la tabla, a partir de TurboC++3.01 esta disponible el modelo 'Flat' tambien.
Cuando escribimos codigo para librerias, un importante y complejo punto en la implementacion es tener en cuenta que las funciones deben tener la flexibilidad necesaria para adaptarse a diferentes modelos de memoria al pasar por el linker. Es instructivo observar las declaraciones de las librerias standard y el modo en que resuelven este tema. El principal detalle es el uso default de punteros 'near', para los modelos de memoria mas restringidos, y punteros 'far' para los mas extensos.
La distincion entre codigo y datos es bastante natural, la sintaxis de C (o Modula-2) obliga a declarar, en una funcion, primero todos los datos antes de ingresar cualquier operacion (codigo). Pero la nocion de STACK tiene una correspondencia menos obvia con lo que observamos en un lenguaje de alto nivel, se trata de algo manejado de modo automatico por el compilador. A lo sumo aparecera en relacion a mensajes de error como 'Stack overflow' o 'Desborde de pila' (tambien 'volcado de pila', en Windows). En programacion de bajo nivel (ensamblador) podemos operar directamente sobre la misma.
Ahora bien, ¿que es la pila?. Es una zona de memoria (no diferente del resto de memoria) requerida por todo programa (la misma cpu lo requiere) para un uso especial. Su funcion, sinteticamente, es la de servir para el intercambio dinamico de datos durante la ejecucion de un programa, principalmente para la reserva y liberacion de variables locales y paso de argumentos entre funciones.
El espacio utilizado para uso de la pila variara segun el modelo de
memoria que utilice nuestro programa. Cuando un programa utliliza el modelo
de memoria SMALL usa un mismo segmento para codigo y stack, 64 Kb
entre ambos.
Suponiendo que nuestro programa opera con tal modelo de memoria, en
la mayoria de los compiladores de BorlandC++, el segmento de datos/stack
presentara el siguiente aspecto, luego de ingresar en la funcion main()
de un programa cualquiera:
|
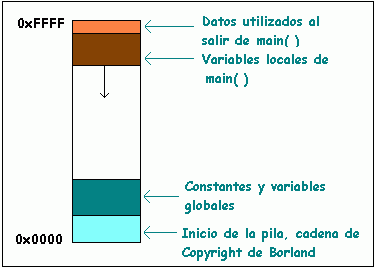
El inicio del segmento(0x0000) contiene una cadena de Copyright de Borland que no debe ser sobreescrita (pues daria el mensaje "Null pointer assignment"), luego se ubican las variables globales y constantes. Los literales, sean 'de cadena' o 'numericos' son tratados como constantes y almacenados en la parte baja. Al final de la pila (desde 0xFFFF) se guardan datos fundamentales para una buena salida del programa, y debajo se extiende una zona usada para almacenar variables locales y datos pasados como parametros, por lo tanto es la parte mas dinamica del segmento (en el grafico la parte en blanco). |
El espacio total del segmento es de 64 Kb, esto significa que el monto de datos que podemos pasar a una funcion sera un poco menor pues hay espacio ocupado por otros elementos. Esta limitacion se puede sortear utilizando otro modelo de memoria, pero por ahora nos centraremos en nuestro ejemplo con modelo small.
Cuando se guardan en la pila mas valores de los que caben se produce un 'stack overflow', un desborde de pila. Las funciones recursivas trabajan haciendo una copia de si mismas y guardandola en la pila, por esa causa es frecuente provocar desbordes de pila de ese modo. Hay muchos motivos para utilizar la pila del modo mas economico posible, y los punteros cumplen una gran utilidad en este caso, por ej al pasar arrays, estructuras u objetos entre funciones a traves de una direccion (solo 2 bytes).
Otros detalles en relacion a punteros. Todo puntero que este dentro de este segmento y apunte a otra direccion del mismo segmento sera un puntero 'near', para apuntar a un segmento diferente deberemos (en modelo small) explicitar un puntero 'far'. Una cuestion interesante es la de si la memoria dinamica se almacena en este segmento o en algun otro. Los detalles en la implementacion de memoria dinamica son en general bastante oscuros y dependen mucho del compilador utilizado, pero si el espacio reservado con 'new' se asocia a un puntero 'near' es claro que la memoria reservada estara dentro de este mismo segmento. Para estudiar este aspecto es recomendable ejecutar el programa en modo debugger y consultar los datos del puntero, el valor de segmento donde se encuentra y el valor de segmento adonde apunta.
Todas las variables, arrays, punteros y objetos en general tienen una duracion determinada en el transcurso del programa. Tales objetos son 'creados' y 'destruidos', o en otros terminos: se asocian sus nombres (identificadores) a una zona de memoria en la cual no puede asentarse otro objeto, y tales zonas de memoria son liberadas para el uso de otros objetos.
La existencia de tales objetos esta determinada segun tres formas basicas de usar la memoria en C++.
1-Memoria estatica
Los objetos son creados al comenzar el programa y destruidos solo al finalizar el mismo. Mantienen la misma localizacion en memoria durante todo el transcurso del programa. Estos objetos son almacenados (en compiladores Borland) al principio del segmento de datos. Los objetos administrados de este modo son: variables globales, variables estaticas de funciones, miembros static de clases, y literales de cualquier tipo.
2- Memoria automatica
Los objetos son creados al entrar en el bloque en que estan declarados,
y se destruyen al salir del bloque. Se trata de un proceo dinamico pero
manejado de modo automatico por el compilador (no confundir con memoria
dinamica). Tales objetos se almacenan en la parte alta de la pila al entrar
en la funcion o bloque.
Este procedimiento se aplica a: variables locales y argumentos de funcion.
3-Memoria dinamica
En este caso tanto la creacion como destruccion de los objetos esta
en manos del programador, a traves de los operadores 'new' y 'delete'.
El sitio donde se almacenan tales objetos se suele denominar en ingles
'heap' o 'free store', traducido como 'monticulo' o 'memoria libre'. Pero
el sitio preciso donde se encuentre tal 'monticulo' depende del compilador
y el tipo de puntero utilizado en la reserva de memoria dinamica.
Cualquier tipo de objeto puede ser creado y destruido a traves de este
procedimiento.
En C y C++ la administracion explicita de memoria por parte del programador juega un rol muy importante, no es asi en otros lenguajes (Basic, Smalltalk, Perl) donde la gestion principal es automatica. La administracion 'manual' permite un mayor grado de flexibilidad pero tambien multiplica la posibilidad de errores. Un modo de gestionar memoria dinamica en C++, aprovechando las ventajas de la memoria automatica, es la implementacion de destructores que sean llamados de modo automatico al salir de un bloque, y que se encarguen de la liberacion de memoria dinamica.
La forma mas simple de almacenar un valor en una direccion de memoria
es a traves de asignaciones. A veces, ante una asignacion fallida, aparece
el mensaje "Lvalue required", veamos que significa.
Las expresiones "R-value" y "L-value" ("rigth-value"
y "left-value"), originalmente significaban algo que puede estar
a la derecha o a la izquierda de una asignacion. Por ejemplo:
int x;
4 = x; //Error en tiempo de compilacion: "Lvalue
required"
El compilador nos informa de que se requiere un 'l-value' a la izquierda de la asignacion. El '4' es un literal numerico, y los literales son tratados como valores constantes, no pueden estar en esa posicion.
Ahora bien, ¿como definir "l-value"?. T. Jensen lo define como: "valor de la direccion de una variable", y Stroustrup como: "algo que esta en la memoria, que ocupa una region continua de memoria". Esto ultimo se ilustra con las siguientes lineas:
int a, b=4, c=5;
a = b + c;
el valor de 'a' sera igual a 9, este valor 9 es producto de "a+b", no ocupa una zona de memoria, no hay un 'nombre' de variable (de una variable) asociado a el, es un valor temporal sin identificador propio. Por lo tanto, al no estar en memoria bajo un identificador, no es un "l-value", por esa razon:
b + c = a; //Error. "Lvalue required"
nos da ese mensaje de error.
A pesar de la definicion de 'lvalue', como aquello "que puede estar
a la izquierda de la asignacion", hay cosas donde esto no se cumple.
Una variable declarada como constante es un 'lvalue', es un objeto en memoria,
pero no puede estar a la izquierda en una asignacion.